Both my day job and my open-source work involve constant use of git and GitHub. These are some useful patterns that I’ve found myself using regularly.
(From this point onwards, I shall abbreviate a “pull request” as PR).
1. the peel-off PR
when do I use it?
I am working on a feature branch
I see some injustice in the code that I wish to fix right there and now, but which is unrelated to the feature I’m adding (eg a small bug, inconsistency or coding standards violation)
what I do
park my work-in-progress (by either committing or stashing)
checkout master
create a new branch
fix the injustice, open a PR
switch back to my feature branch and continue working
rebase against the injustice branch later, once it’s been merged
This satisfies both my desire to quickly fix the unrelated problem, and keeps the feature branch clean to make reviewing easier.
2. the optimistic branch
when do I use it?
There is an unmerged branch (branch-A) which cannot be merged right now (eg CI build broken, code reviewer busy, etc)
I need to make another change that relies on the code in branch-A
what I do
create a new branch (branch-B) off branch-A
once branch-A is merged into master, I rebase branch-B against master and resolve any resulting conflicts
bugfixes from branch-A can then be rebased into branch-B
This approach carries the risk of conflicts if drastic changes are made to branch-A, but the optimistic strategy tends to work out fine in 95% of cases
3. the heads-up PR
when do I use it?
I’m making a change that I assume doesn’t really need reviewing
I would still like my teammates to know about it
what I do
make change on branch
raise a PR
merge the PR myself immediately
This methods doesn’t block me from carrying on, but GitHub still notifies my teammates of a PR via email, so anybody could still potentially comment on the change if they find it objectionable
4. the sneaky commit
when do I use it?
after the code has been reviewed and merged into master
I need to make a small change (eg a copy change or bugfix) that’s not even worth notifying others about
what I do
just push the new commit to master.
5. the roger roger comment
when do I use it?
I’ve received actionable feedback from a code review on a branch
I’ve made fixes based on the feedback
what I do
I comment on the PR which includes the ref of the fixes commit
GitHub cleverly augments commit ref numbers with links to the diff, so that my colleagues:
are notified of my change via email
can easily click through to the commit diff
know that they can continue the code review
6. the creepin’ commit
when do I use it?
I discover that I’ve introduced small formatting bugs (eg unnecessary whitespace, missing newline at the end of file, etc), or
A logical code change really belongs in the previous commit, or
My code isn’t committable (eg some tests are failing) but I still would like to be able to roll back to this point, so I can experiment safely
what I do
in the first two cases, I amend the previous commit
for the third case, I have a work-in-progress (creeping) commit, which I progressively amend (or roll back to, if the experiment fails) until I reach a bonafide commit point
7. the forced branch
when do I use it?
I need to amend an remotely-pushed feature branch, eg I’ve explained something badly in a commit message
what I do
I amend the commit locally
I force-push the feature branch to the remote repo
While force-pushing to a remote branch is supposed to be a big git no-no, my experience is that there are rarely problems with this approach (as long as it’s only to the branch, and not to master). GitHub deals well with force-pushing to a PR branch, ie it doesn’t lose the comments on the previous commits, etc
8. the reformat peel-off
when do I use it?
I want to both change and reformat some code
what I do
I make a separate commit onto master, which contains only the reformat
I rebase my branch against master
This way, the diff on the branch with the change is much cleaner and more obvious for a code reviewer, because it doesn’t contain the reformatting
9. the prototype PR
when do I use it?
I want to get feedback on my ideas before implementing lots of code
what I do
I hack something together on a branch
I raise a PR for it, the intention of which isn’t to deliver finished code, but rather to be a starting point to discussion.
I close the PR (and kill the branch) when consensus has been reached on the next steps
I create another branch and PR, with proper code this time
I used to think that PRs were supposed to be raised when the code was finished. Now I have really grokked that “Pull requests are a great way to start a conversation” - GitHub’s functionality around PRs (such as inline commenting, replies, notifications and diffing) is excellent for facilitating code and design discussion, and can prevent developers going too far down dead-end paths.
Recently, I interviewed a team lead, working in a large financial services company, about ensuring a high level of quality for a large ETL migration project that his team had delivered.
Project background and challenges
The team had a difficult job on their hands. They were replacing a gnarly and troublesome legacy system, which had evolved many (undocumented) data flows over time. The new system would be mission-critical, delivering data feeds to multiple departments within their company. Operating in a regulated field, the team had to deal with all of the same constraints that Martin Thompson’s team were facing - a need for traceability, completeness and the ability to “explain your working”. On top of that, the team was distributed, split between the UK and Ukraine.
The application was to be hosted on Windows and would use Microsoft SQL Server as the data store. At the start of the project, the team evaluated various technologies for their development stack, and settled on writing the ETLs and feeds in C# with Database Projects. This stack proved a good fit for the team’s mix of OOP and SQL development skills.
A build pipeline baked in
The team set up a build pipeline from the very start. Time was invested upfront into figuring out how to write low-level tests and minimise testing dependencies between the schema, the feeds and the ETLs.
The schema objects, the ETLs and feeds each had their own independent build and test stages. Combinations of the three (that successfully passed the individual tests) were then bundled together and put through a separate integration and performance test pipeline. The entire pipeline was fully automated end-to-end: a change in version control to any one of the 3 components would first be exercised at unit level and upon success, a new deployment artefact would be bundled and automatically promoted to the next build stage. The pipeline was also portable: any developer was able to check out the code and run the whole pipeline on their local development machine. A successful run, from code change to production readiness took around 2 hours to complete.
For breaking changes, version control branching was used. With TeamCity, it was easy to clone the entire pipeline and configure the clone to execute off a branch. This meant that the branch code was already thoroughly tested prior to being merged into the trunk, leading to fewer integration breakages.
Unit testing
The team followed the model of the test pyramid, with a large amount of tests written at the unit level. Because the feeds and ETL code were written in pure C#, it was possible to use C# tools like MSTest to run the unit tests, while mocking out the schema. This mocking approach allowed making schema changes without breaking the feed and ETL unit test phases, and for developers to work on those components independently. Test-driven development was used to get fast feedback on the code being developed.
Integration testing
The integration tests were split into two stages, one for the database and one for the feeds. As well as verifying the component integration, they played the role of acceptance tests for the business requirements. There were few, relatively large integration tests, each covering a complete system requirement for a single consuming downstream system.
The team followed acceptance-test-driven development. Before a new feature was implemented, a conversation would take place between the developers, BAs and stakeholders. Afterwards, the developers produced new input data and the expected output data. As both the input and output was in the form of human-readable files, the BAs were in a position to check and sign-off the test data changes before implementation started.
At the start of the project, the team explored the possibility of abstracting the database in the integration tests, but decided not to pursue this strategy because the technical costs outweighed the yielded returns. Input data was mostly hand-crafted, and then augmented by special cases extracted from production data. The team created custom libraries for comparing expected and actual output data, which were able to ignore differences in id and timestamp fields, and allowed tolerances when comparing numeric fields. The integration test suite also included performance tests, run with data volumes of different t-shirt sizes (small/medium/large).
The path to live and releasing
By the time a change had successfully travelled through the pipeline, the team had a high level of confidence about its correctness, and would ideally liked to deliver continuously into production. The team’s tricky change management constraints meant that this was not possible; nonetheless, the pipeline made sure that there were virtually no surprises when the time came to release. Because each release contained numerous changes, a short exploratory testing phase on a production-like environment was necessary prior to each release.
The end result
The team was able to successfully replace the legacy system and the new system has been running without problems in production for more than a year now. Along the way, the team experienced no failed releases. Only a single urgent production bugfix - to fix a performance problem - was ever necessary. The problem was not uncovered during testing because of differing configurations between the test and production environments. Because the pipeline was fast enough, the team were able to put the bugfix through it just like any other change, and didn’t have to expedite it virtually untested, as often happens in such situations.
If you are writing browser-driven tests, the Page Object pattern is a really useful abstraction to use. Let’s assume that our test wants to interact with the navigation bar on a complex page (eg The Guardian homepage):
We could create methods for doing this on the page object class:
However, for a page that has so much going on, putting every access method on the page object class will mean that your page object will have tens of methods on it, making it very hard to comprehend and maintain.
The solution: panel objects
One very neat trick is to break the page object up into panel objects. That really helps reuse as well, because often the same panel appears on several pages.
Thus, your page object would probably look like this:
This way, you can easily reuse the NavigationBar class on another part of the site, and in case the markup changes, you only have to change it in one place.
So, once you’ve defined a homepage() method somewhere which loads a WebDriver and launches the homepage, you can use a really nice DSL for navigating to the Sports page in your tests:
I remember going to the dentist one time and being told off for having a bad brushing technique. As well as causing mild embarrassment, the rebuke got me thinking about feedback cycles - assuming that I adjusted my brushing, when would I notice a difference? Plaque build-up isn’t something that’s easy to pick up at home, and most people don’t go to the dentist more often than every 6 months (if that often at all) - so short of marrying a dentist, or using those plaque-marking tablets (which leave a nice blue glow on your teeth), you’re left with a 6 month feedback cycle. Which sucks.
With software, feedback can be cheap and frequent, although bizarrely, most product teams in the industry are content with just whatever came out of the few functional and non-functional tests run by their dedicated QA team. By virtue of doing automated testing, TDD, continuous integration, code reviews, retrospectives, smoke & perf testing, the Government Digital Service (GDS) team that built GOV.UK (the UK central government’s publishing portal) is already well ahead of the curve, but those things aren’t really new - all good teams are doing most of those nowadays. I’ve chosen to highlight the techniques below because either I haven’t seen them in action before, or because I was rather surprised to see them being used by a 250+ person team running a nation’s critical IT infrastructure.
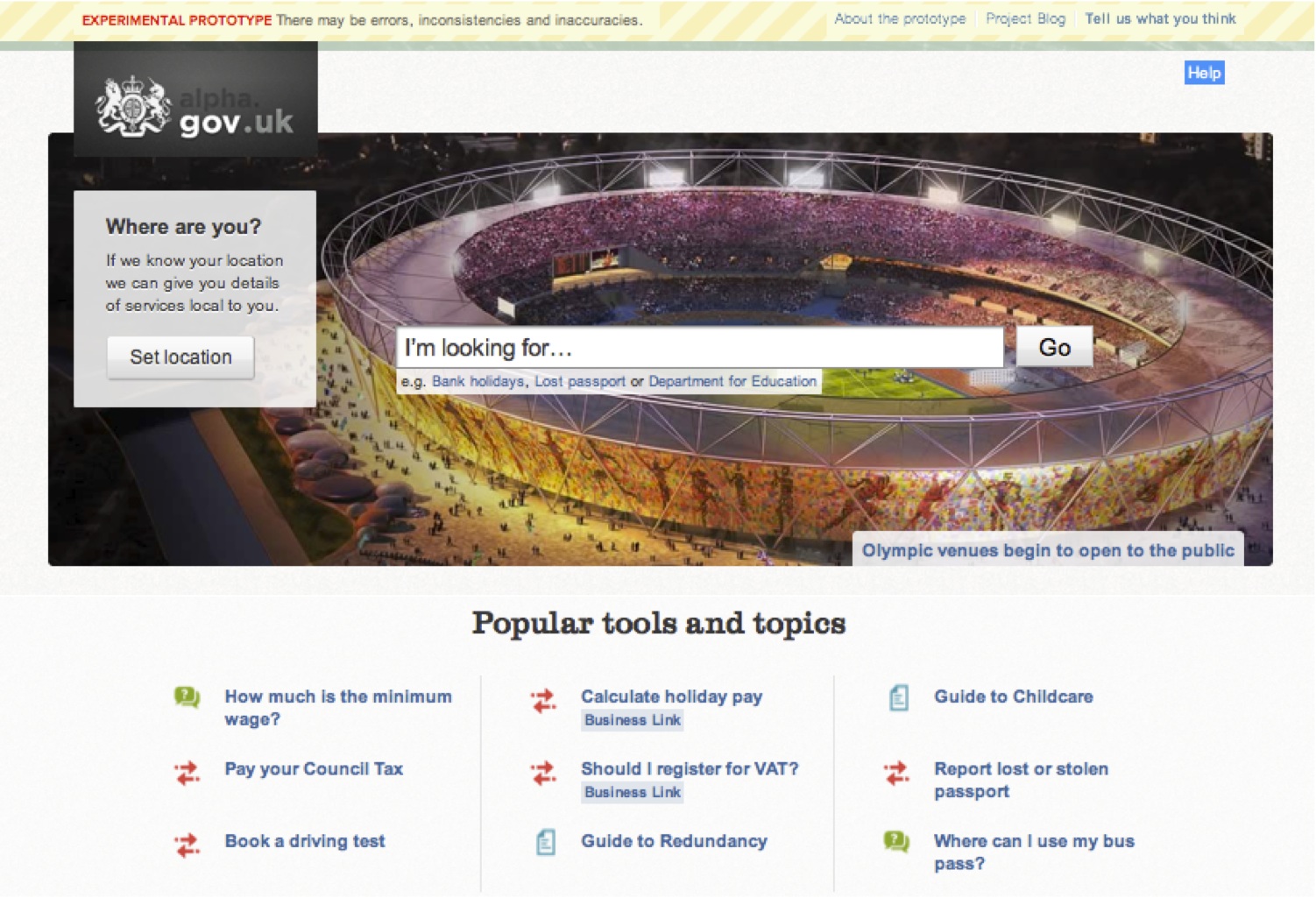
Instead of beginning to develop GOV.UK in stealth mode, GDS built a prototype - the alpha version - and released it. Alphagov, as it was called, was built in 12 weeks, cost £261,000 and was delivered only a day late - and the 12 weeks included time for hiring and building the team. You can still see Alphagov on the National Archives website - compared to GOV.UK now, it looks very rough, but that was intentional - the alpha was designed to optimise learning, not to deliver a finished service (a minimum viable product, in Lean Startup lingo).
The GOV.UK alpha at launch. Tom Loosemore, GDS Blog
Not every team has the guts to do this - releasing early left the GOV.UK team exposed to criticism (eg check out the ruckus that erupted in the comments of the announcement that the alpha wasn’t going to focus on accessibility), but also allowed them to gather invaluable feedback - from fellow civil servants, from readers of the GDS blog, via Twitter, email and through user feedback tools such as GetSatisfaction. Driving real traffic through the site exposed problems with browser/device combinations that in-house testing would never picked up. More importantly, the alpha allowed gathering enough data to decide whether the team’s underlying approach was sound, and whether the project should be continued in its current form.
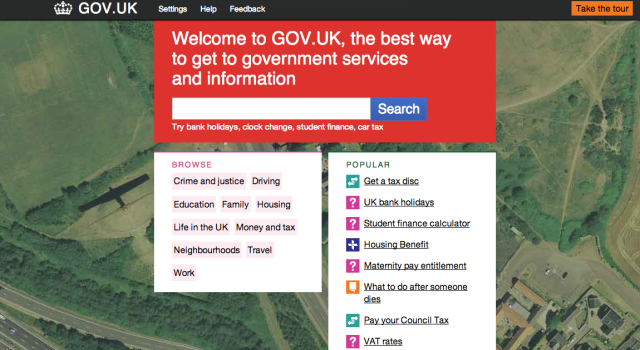
The beta
The GOV.UK beta when it was first launched. Tom Loosemore, GDS Blog
The GOV.UK beta took several months to develop and was a more complete, end-to-end prototype. It allowed the team to start observing usage patterns, and confirm or invalidate assumptions about user behaviour. It allowed the team to refine the content formats and editorial style, refine the content itself, practice deployments, so that when it came to switch the service on, it was no more than re-routing live traffic (which the team practised beforehand as well); the site had effectively been live for months already.
One of GDS’s design principles is “design with data”. During the alpha and beta, the GOV.UK web analytics team pulled visitor traffic data from sites that GOV.UK was going to replace - Directgov, Business Link and individual departmental websites, and used it to:
Decide whether to migrate or drop content. To keep GOV.UK as lean as possible, not all Directgov/Business Link content was migrated across; the visitor analytics data helped make the decision about what to migrate and what to leave.
Identify nuances around specific user needs. The long tail of search terms (and related terms) exposed a number of variations of the same user goal. The most popular ones could be grouped and answered by separate “nodes”.
Identify which browsers and devices to support and test with. helped figure out which browsers to support and not to support (eg allowed team to decide to drop support for IE6, make mobile and tablets a focus)
Sorting user needs, Tom Loosemore, GDS Blog
Post-launch
While a new feature is being built, the product and analytics team would define what success looks like for that feature. As an example, a user is considered to have successfully engaged with the content using the ’guide’ format if they spend at least 7 seconds on the page, or click a link within the body of the page. With the definition in hand, tracking of those metrics is implemented, allowing automatic measurement of the success rate post-launch. Some of this information may then be pushed into the GDS performance platform and presented on dashboards or internal tools. GOV.UK analytics also enables in-depth ad-hoc analysis of specific features or formats. Since there are strongly defined seasonal trends in GOV.UK traffic, the visitor data can help with capacity planning in the user support team.
Product dashboards are a tricky proposition: if they fail to present the data clearly, they end up being ignored (or worse still, being misleading), making all the hard work of exposing and processing the data a complete waste. In too many products, the dashboard is an afterthought, added by a developer in his spare time. By contrast, the GOV.UK dashboards - one for citizen content and another for the Inside Government content - has been given as much design attention as the rest of the site. I really like their simplicity and focus - the GDS Performance team has done a really good job.
GOV.UK replaced DirectGov and Business Link in Oct ‘13
For example, the above graph makes it obvious that GOV.UK is receiving significantly more traffic now than its predecessor sites were getting this time last year.
Being able to clearly categorise content by traffic and performance gives the content teams clear priorities about which content to improve first (ie high-traffic, poor-performing content).
It’s heartening to know that a bunch of those services will be redesigned in the near future as part of the Government Digital Strategy service transformation, invariably lowering the per-transaction cost in the process.
A couple of days ago, I overheard two GDS developers talking after seeing a user testing session, with one saying to the other: “There’s nothing like user testing to show you all the things you’ve done wrong” (this is a paraphrase, I don’t recall the exact words). It’s obviously tough to watch users rip the work you’ve spent all that time and effort doing to shreds, but still a million times better than the same happening after the feature has been launched.
Constant user testing of different parts of the site is just one of the main responsibilities of the user research team:
Once the website data starts telling us what the users are doing, we’re pretty sure our colleagues will want to know why – and that’s where the Insight and Usability Team can help.
GOV.UK underwent numerous rounds of lab testing, with each round focusing on a subset of features and content (eg the homepage, search, or specific calculators); the users were selected to be as close to the target audience of the content or tool being tested. To reduce the amount of bias, the user group included diverse ages, sexes, professions and varying skills of online proficiency. Each round uncovered new and interesting usability failures, and the team responding with several major redesigns, as well as hundreds of minor tweaks.
Some features, like the homepage, took several iterations to get right (and more changes are being planned in the future):
Homepage at the Beta launch
Homepage that looks less like a parking page
Homepage without the confusing iconography
Homepage design at the time of launch (where search takes a back seat)
Notice how in the final version, the search bar is de-emphasised. This change was made as a result of user testing that showed that users who preferred search would come in through Google anyway; those coming in through the homepage needed to be able to browser through categories to get to the content they were looking for. Users also preferred seeing all of the categories and their descriptions above the fold of the page, as it gave them a better sense about the scope of the site.
It’s been GDS’s view from the very beginning that compliance with technical accessibility standards (eg WCAG2.0 ‘AA’), while checking the legal tick-boxes, would in itself not be sufficient to make GOV.UK usable and useful for disadvantaged users. Consequently, success would depend on doing extensive testing, and the testing would have to cover the content, not just the interaction design - here’s a post about user testing with deaf customers at the DVLA that illustrates this point well.
Checking colour contrast standards compliance with the WCAG Contrast Checker Firefox plugin
Internal testing
From the start of the GOV.UK beta, Léonie Watson (a recognised accessibility expert) has been working with the team as a consultant alongside Joshua Marshall, the GOV.UK accessibility lead. Léonie and Joshua run continuous internal testing on parts of the site that are in active development: Léonie tests from the point of view of an expert screen reader user, and Joshua runs the site through various simulators and accessibility checkers, as well as interacting through different assistive technologies, such as screen readers, magnifiers, and speech recognition software.
Simulating common types of colour blindness with Sim Daltonism, a OS X-based colour blindness simulator
External testing with users
Each distinct GDS product ideally sees at least two user testing rounds before its launch: one round at the end of an alpha, and another one at the end of a beta phase, so that it is possible to measure whether improvements have been made. If the product has a similar interaction to something that has been previously tested (eg if a transaction uses the same layout and colour schemes) then it may only get one round with disabled users. The participants on the trials are chosen to represent a variety of user groups: blind screen-reader users, screen magnification users, deaf British Sign Language users, keyboard-only users, speech-recognition software users, Dyslexic users, and Aspergers or autistic users.
Blurred vision simulation with the NoCoffee vision simulator plugin for Google Chrome - the fonts are magnified for legibility
So what has the testing found?
Similar to user testing with other user groups, each round of testing with disabled users showed that the site’s accessibility was improving, but still exposed new (lesser-severity) problems. The homepage and search were two areas that experienced large churn, with many smaller adjustments done to colour schemes, links and markup structure.
GOV.UK is operated using the DevOps model, which is really just a way to say “developers and operations people building live services together” - the polar opposite of the “throw it over the wall” mentality that breeds as a result of having separated operations and development teams.
The deal
How it works in practice: a sizeable proportion of the developers have full unrestricted access to the production servers, as well as the deployment and configuration management code repositories. Furthermore, they are actively encouraged to configure their own production systems, write the deployment code and deploy releases themselves. This excuses them from having to do heavyweight, painful handovers, but it does mean that they have to fix production if they break it.
The infrastructure and ops team takes care of spinning up new machines, sorting out the network configuration, various data storage options (with redundancy, failover and backups), security and hardening, and many other things. The ops guys make sure that the platform runs smoothly, and they put the tools in place to expose important information from production (like logs, monitoring counters and alerts). Because they aren’t on the hook to fix application issues, they have time to help the developers out with setting up development and test environments.
A developer’s perspective
idea 7:45am, code committed at 8:01am, code reviewed by 9:56am, tested by 10:10am, deployed on Govt infrastructure 10:20am @gdsteam rocks!
For an application developer such as myself, this is a really good setup:
I have a very good understanding of how my application is doing at any time
I get almost instantaneous notification when production problems occur
because the release cadence is driven by the application teams, I can release pretty much whenever there’s a slot available
I am less likely to develop something that will work badly on production, because I have a tested the code in a development environment that is very similar to production
by writing the deployment and configuration code together with the infrastructure team, my deployment bugs and system misconfigurations are caught very early.
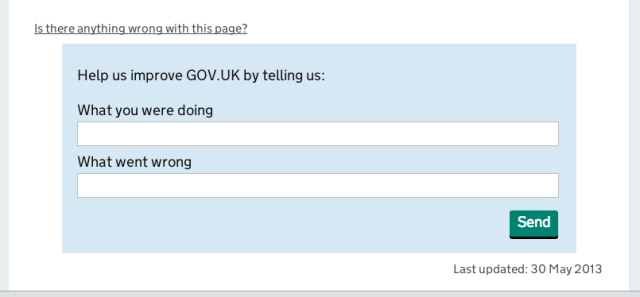
There are a few ways in which a visitor to GOV.UK can contact GDS directly. The most obvious one is through a standard contact form, but it can also be done through Twitter or the GDS blog. Additionally, every page in the citizen section of the site offers the opportunity to leave feedback:
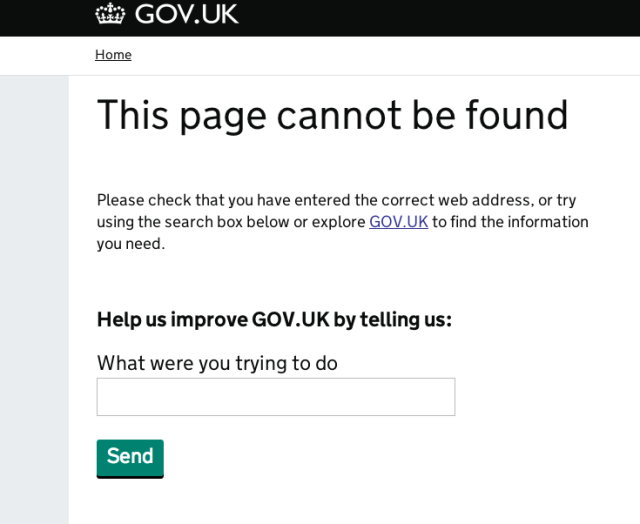
Even when a user encounters a broken link, the site solicits feedback:
Each user submission is funnelled into the GOV.UK ticketing system and is handled by the User Support team, who help the user whenever they can, or pass the query through to the relevant part of government when they can’t.
User feedback as monitoring
Unclear or problematic content invariably generates more user feedback, so a spike in user complaints tends to mean that there is a breakage somewhere on GOV.UK or a service that it links out to - as soon as such a spike is identified, the underlying problem is investigated and the relevant GDS or departmental team is immediately notified. In effect, this process acts as another layer of monitoring of the system’s health.
Seeing the trends
To identify longer-term trends, the team looks at both the absolute numbers of user questions, as well as the ratio between amount of page traffic and the number of questions. The content teams then use aggregated reports of the user feedback to really dig into the problems and understand the cause of the confusion or frustration.
I am pleased to announce the release of DbFit 2.0.0 RC5 - it’s been a while since the last release. The ZIP archive can be downloaded from the DbFit homepage.
The highlights:
Support for encrypting database passwords - if you are working in an environment where you aren’t allowed to store database passwords in plaintext, you may wish to use the encrypt utility that ships with DbFit to encrypt the password.
Oracle: support for the BOOLEAN data type
As always, there’s a whole host of minor improvements and bugfixes. You can find all the details on the “What’s new” page.
 The GOV.UK alpha at launch. Tom Loosemore, GDS Blog
The GOV.UK alpha at launch. Tom Loosemore, GDS Blog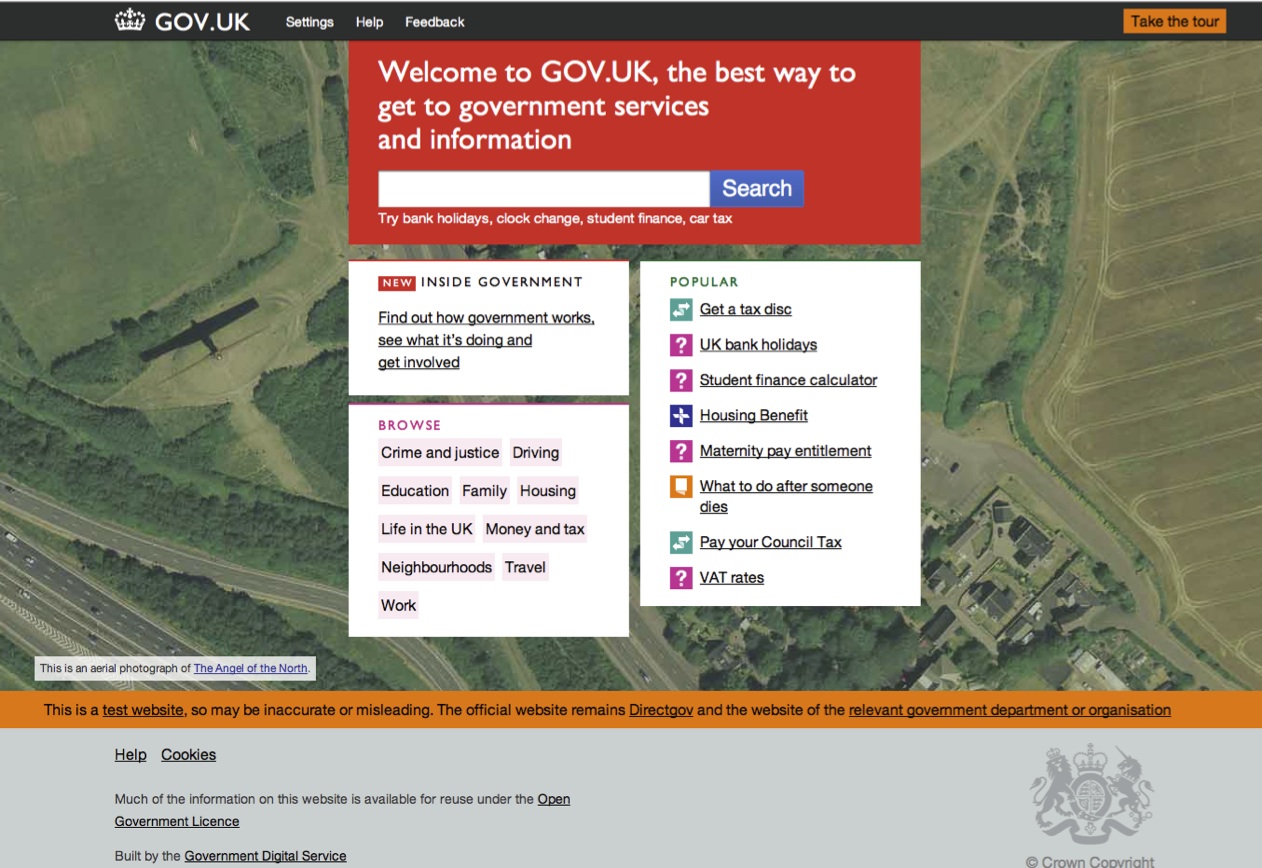 The GOV.UK beta when it was first launched. Tom Loosemore, GDS Blog
The GOV.UK beta when it was first launched. Tom Loosemore, GDS Blog How the redirection works, Paul Downey, GDS Blog
How the redirection works, Paul Downey, GDS Blog Sorting user needs, Tom Loosemore, GDS Blog
Sorting user needs, Tom Loosemore, GDS Blog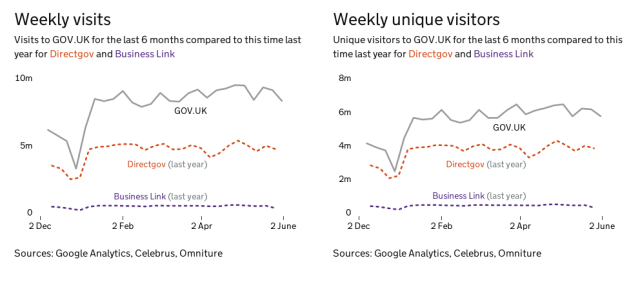 GOV.UK replaced DirectGov and Business Link in Oct ‘13
GOV.UK replaced DirectGov and Business Link in Oct ‘13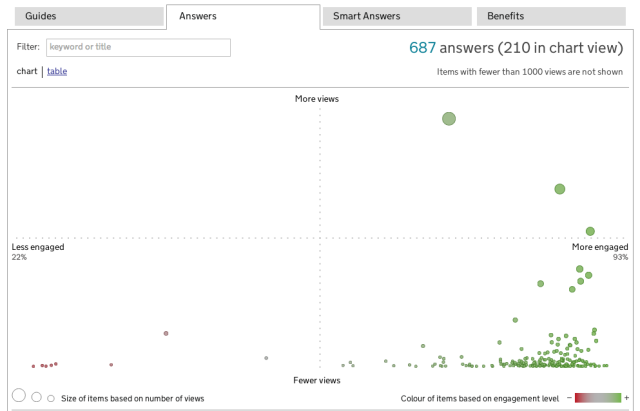
 Homepage at the Beta launch
Homepage at the Beta launch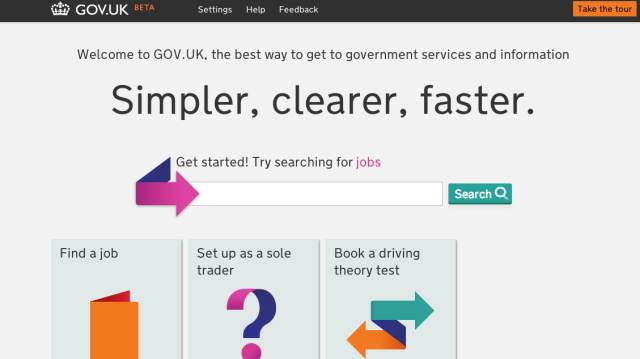 Homepage that looks less like a parking page
Homepage that looks less like a parking page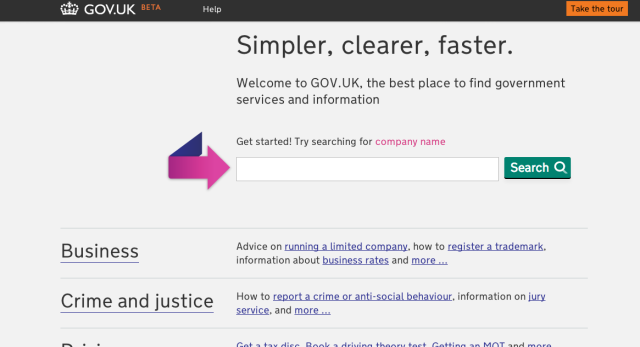 Homepage without the confusing iconography
Homepage without the confusing iconography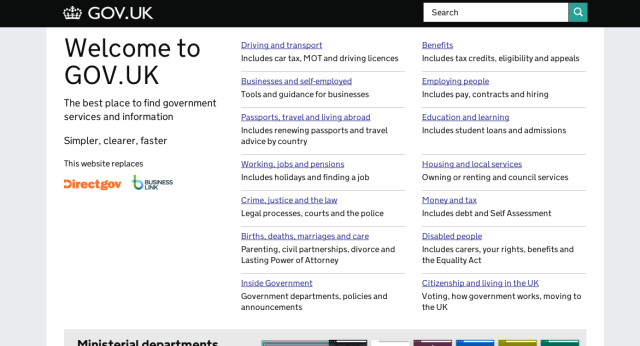 Homepage design at the time of launch (where search takes a back seat)
Homepage design at the time of launch (where search takes a back seat)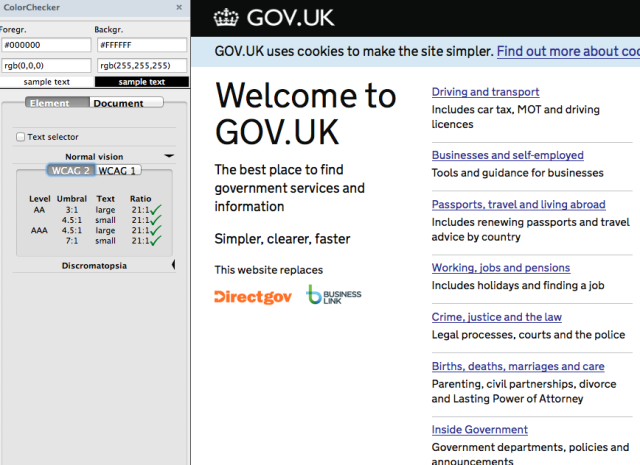 Checking colour contrast standards compliance with the WCAG Contrast Checker Firefox plugin
Checking colour contrast standards compliance with the WCAG Contrast Checker Firefox plugin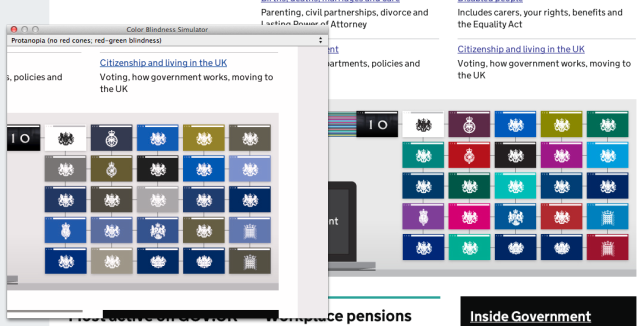 Simulating common types of colour blindness with Sim Daltonism, a OS X-based colour blindness simulator
Simulating common types of colour blindness with Sim Daltonism, a OS X-based colour blindness simulator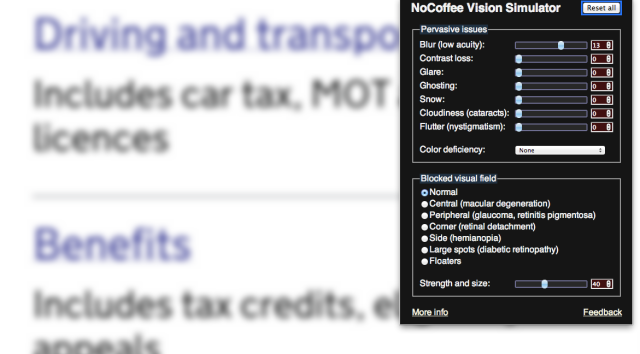 Blurred vision simulation with the NoCoffee vision simulator plugin for Google Chrome - the fonts are magnified for legibility
Blurred vision simulation with the NoCoffee vision simulator plugin for Google Chrome - the fonts are magnified for legibility